Deep Evidence Regression for Credit Risk
Uncertainty Quantification Class Project, 2023Machine Learning is widely used in Credit Risk applications. Quantifying uncertainty in risk prediction is crucial, and uncertainty-aware deep learning models are valuable. This study applies Deep Evidence Regression to predict Loss Given Default, extending the methodology to Weibull-generated target variables. Simulated and real-world data demonstrate the approach's effectiveness.
arXiv Github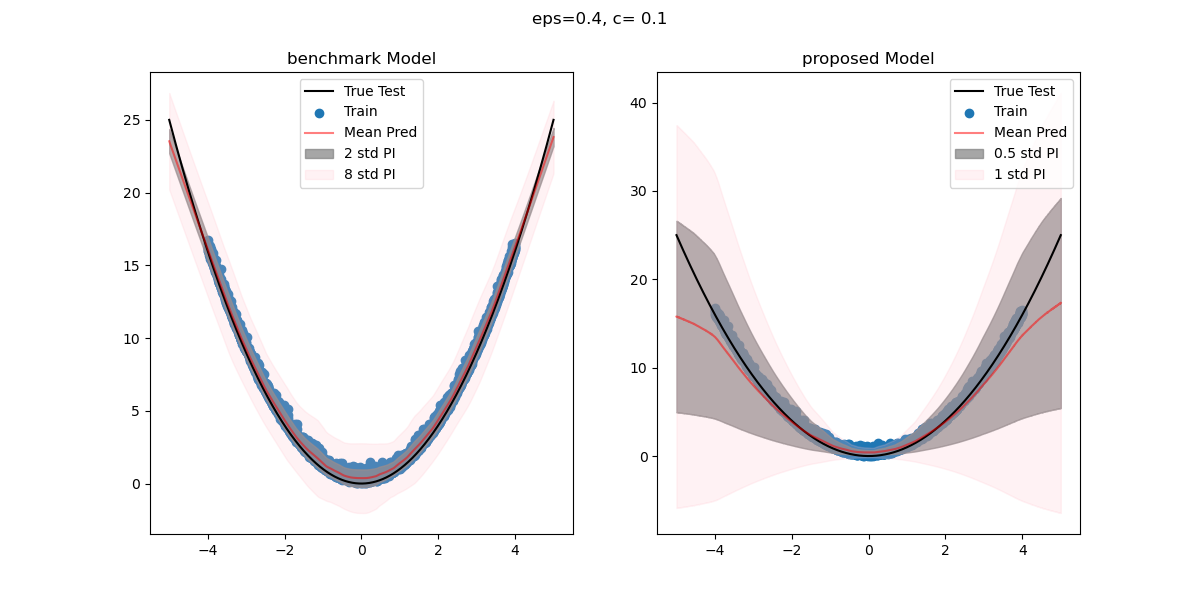
Food Recognition and Recommender System
Georgia Tech Machine Learning Class Project, 2022Used ResNet50 CNN architecture with transfer Learning to achieve a Top-5 validation accuracy of 91% on food images. Applied Collaborative Filtering with the SVD algorithm on the food rating dataset to recommend the best recipes to a user.
Details Github.jpeg)
Forecasting of commodity price structure using HMM
Georgia Tech Computational Statistics Class Project, 2023Understanding the dynamics of future curves is crucial for traders and investors in the commodity markets. By analysing the contango or backwardation of future contracts, they can gain insights into market expectation of future supply and demand conditions and adjust their trading strategies accordingly. We have developed a predictive model using Eigen value decomposition and HMM-GMM to provide signals for shift in price structure of Brent futures, that can help inform decision-making.
Details Github
Forecasting Yield Curve with Gaussian Process in PyTorch
Data Driven Investor, MediumThe US Treasury yield curve is important as it serves as a vital indicator of the market’s expectations about future economic conditions and interest rates. Forecasting the yield curve provides valuable insights for investors, policymakers, and analysts, aiding in making informed decisions regarding investment strategies, monetary policy, and risk management. In this article I explore the use of Gaussian Process regression, a Bayesian Machine learning framework to forecast the yield curve and the corresponding prediction interval.
Details Github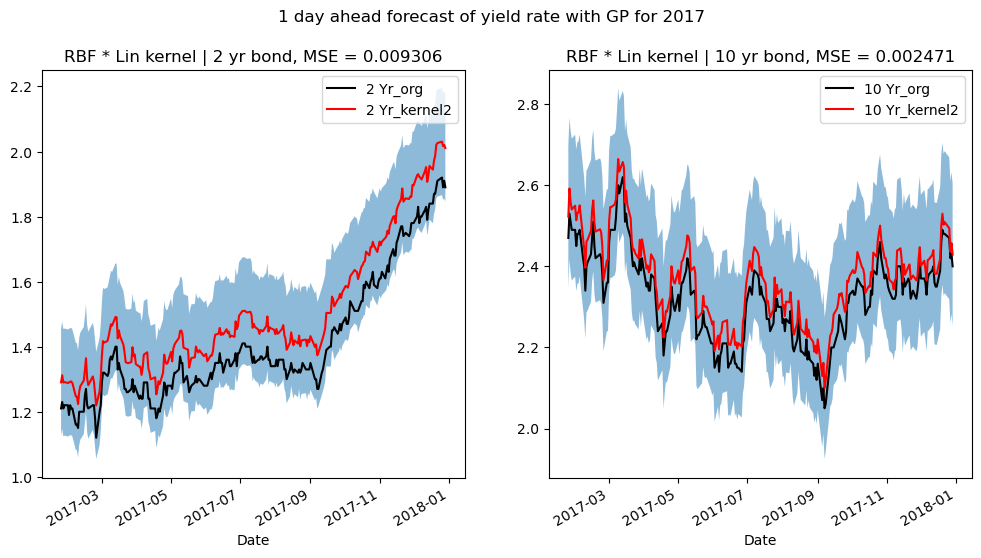
Time Series Clustering for grouping stock prices during Covid
Derive the patterns in stock price rebound trajectory during the covid shockThe onset of the Covid pandemic brought a profound shock to the financial markets in early 2020. Major indices and stocks took a resounding hit, with SP500 showing a decline of about 34% from its February high to its March 23 bottom. This analysis aims to uncover groups among the S&P 500 stocks in their drop and rebound trajectory shown during Covid and identify the drivers behind them.
Details Github
Statistical and Machine Learning theory
This repository is a collection of various mathematical and statistical proofs, related to Machine Learning, Deep Learning and Statitical Learning. The repository includes proofs and examples for various concepts, such as Maximum Likelihood Estimate, Bayesian inference, Regression/Splines, Monte Carlo Markov Chains, Hidden Markov model etc. Whether you're a student, researcher, or enthusiast, this repository has something for everyone, and I hope you'll find it to be an valuable resource in your pursuit of knowledge. Github
Gaussian Mixture Model for MNIST data
Fitting GMM model with both PCA and low rank approximationThis work applies a Gaussian Mixture Model to MNIST data, and compare it with k-means. The EM algorithm is used to fit the model, and two versions are tried: one with PCA and other with low rank approximation.
Github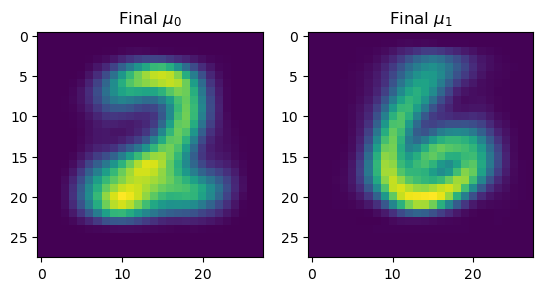
Spotify Music Popularity
Georgia Tech Regression Analysis Class Project, 2022This study explores the complex features associated with music and their impact on a song's popularity on Spotify. We have employed Linear Regression to identify the key factors contributing to a song's traction. Lasso Regression and VIF have also been used to remove multicollinearity among song features. Our findings indicate that the influence of these factors is more decisive for newly-released songs and tends to plateau after a few years.
Details Github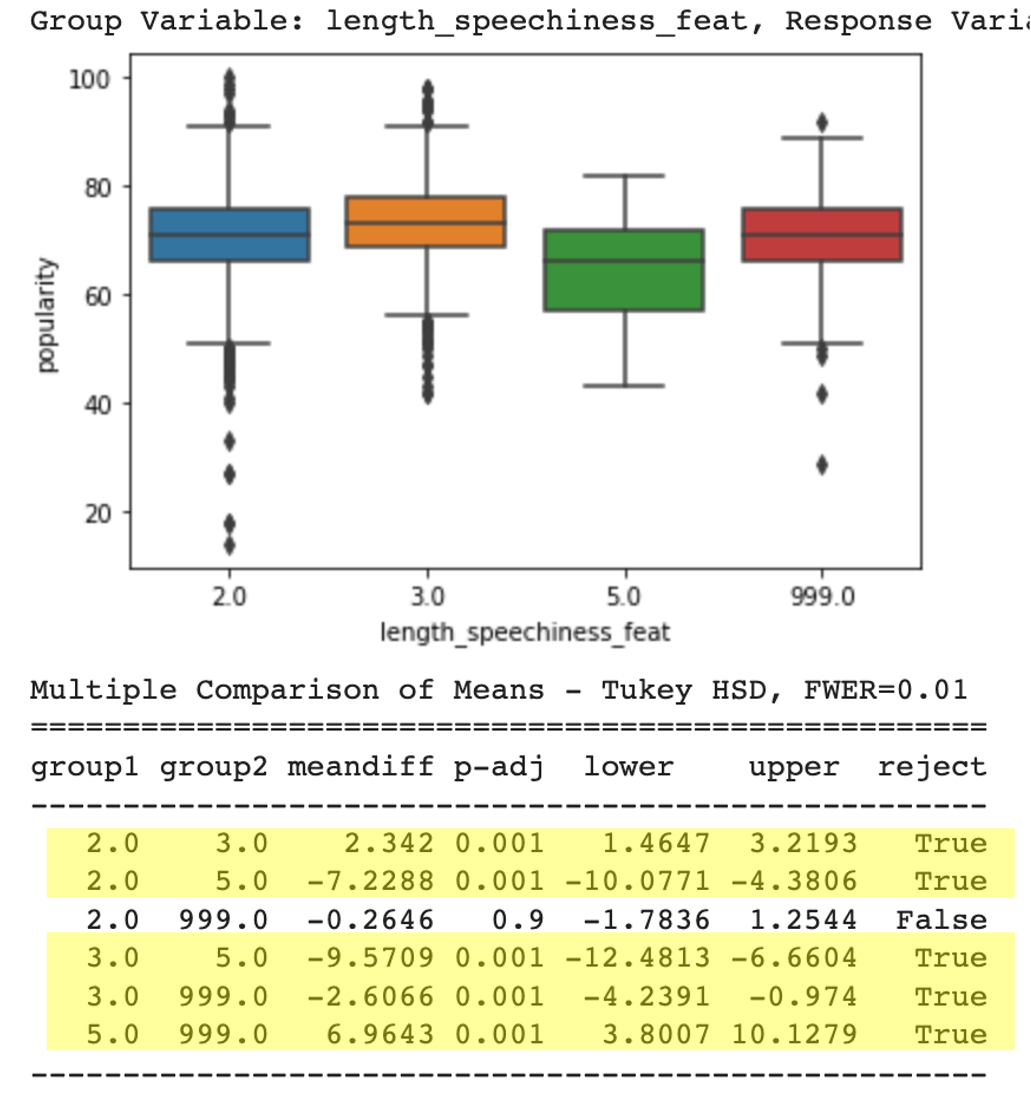
Norm Learning with MCMC Sampling
Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, 2021There is much interest in techniques that allow agents to represent and reason about social norms that govern agent interactions. Much of this work assumes that norms are provided to agents, but some work has investigated how agents can identify the norms present in a society through observation and experience. However, the norm-identification techniques proposed in the literature often depend on a very specific and domain-specific representation of norms, or require that the possible norms can be enumerated in advance. This paper investigates the problem of identifying norm candidates from a normative language expressed as a probabilistic context-free grammar, using Markov Chain Monte Carlo (MCMC) search.
Details Github
Portfolio Optimisation with Kernel Search
Bachelors Thesis, VGSOM, IIT KGP, 2019Index Tracking problem deals with determining a portfolio of assets whose performance replicates, as closely as possible, that of a financial market index (or any arbitrary benchmark chosen), measured by tracking error. Enhanced index tracking improves upon the original problem of Index Tracking by additionally trying to maximise the excess return of the tracking portfolio (over the benchmark) while limiting tracking error, or in other words the optimal portfolio is expected to outperform the benchmark with minimal additional risk over the index.
Details Github
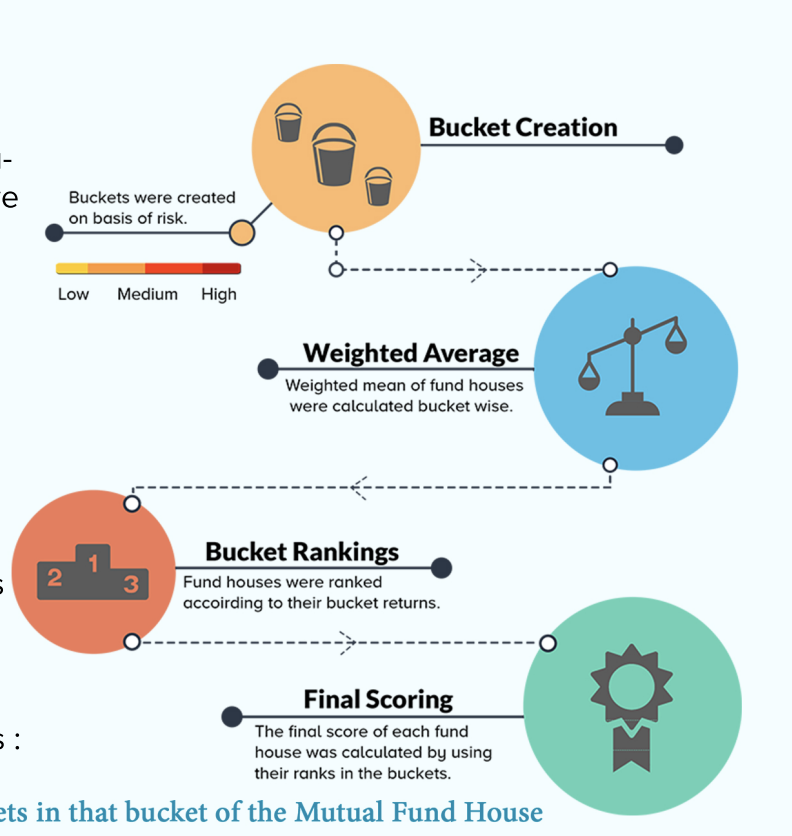
Analysis/Ranking of Mutual Funds in India
Inter Hall Data Science, IIT KGP, 2018Captained a gold-winning team of 20 members to develop an analytics framework to rank Mutual Fund Houses. Applied LSTM for multivariate temporal forecasting of Net Asset Values (NAV) of mutual funds and Vector Auto Regression (VAR) for quantifying responsiveness of the fund houses against macroeconomic anomalies and shocks.
Details